“Filters” are computer programs that take plain text as their standard input (which can come from a file or be the result of another computer program), change it into a format that can be understood, and then send it back to the computer as their standard output. Linux has a variety of filtering options. Some of the frequently used “Filter” commands are “more, less, sort, uniq, wc, and grep”.
more
- Use the “more” command for large file analysis. The data from the huge file will be shown in page format. The “page up” and “page down” keys are not functional. We must hit the “Enter” key in order to show the new record.
more mtab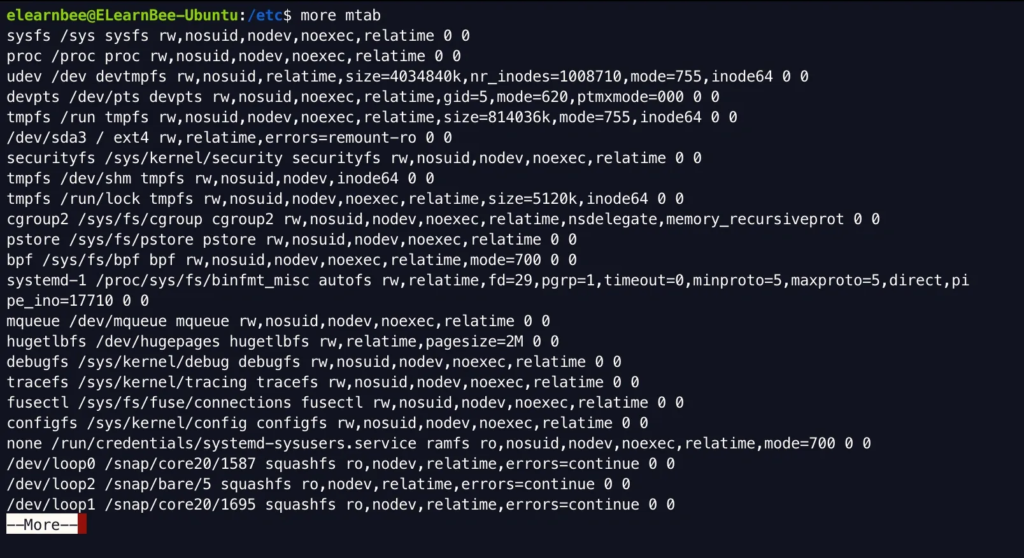
less
- “less” is similar to “more”, however it works quicker with huge files. The data from the huge file will be shown in page format. The “page up” and “page down” keys will function. We must hit the “Enter” key in order to show the new record.
less mtab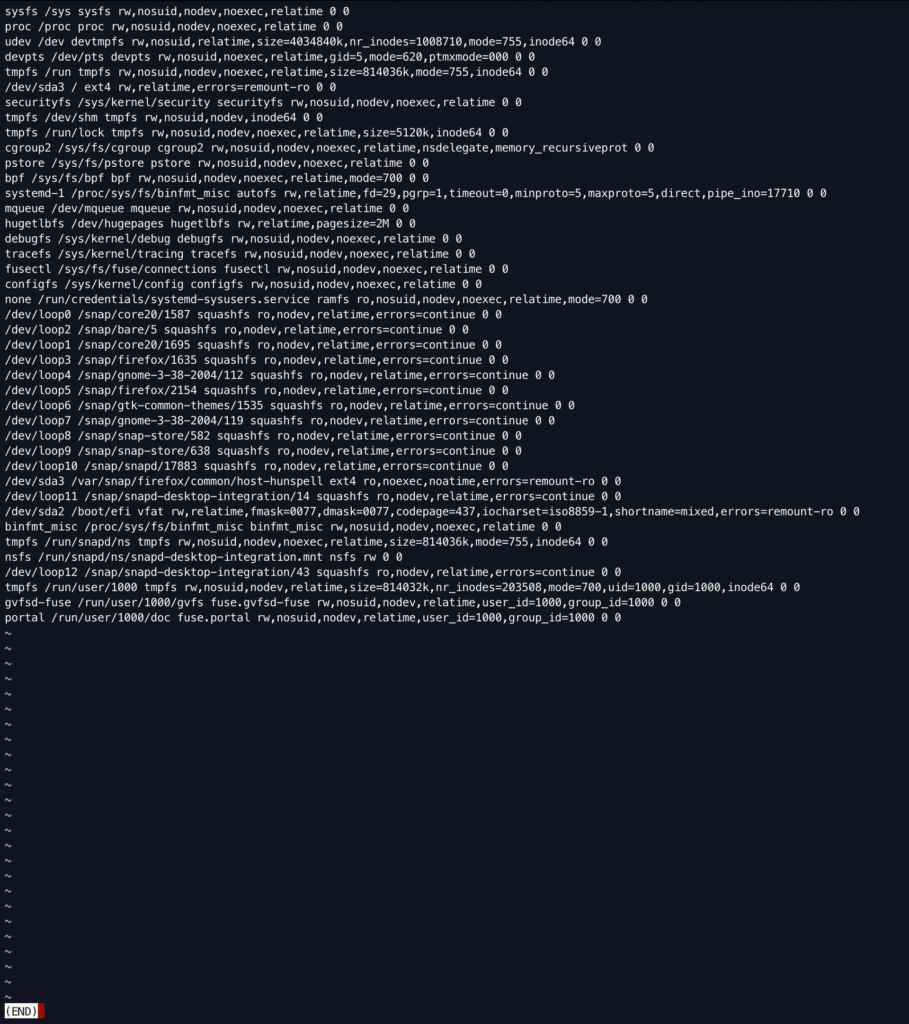
sort
- The “sort” command is used to sort lines in a text file or from standard input in an alphabetical order.
sort months.txt 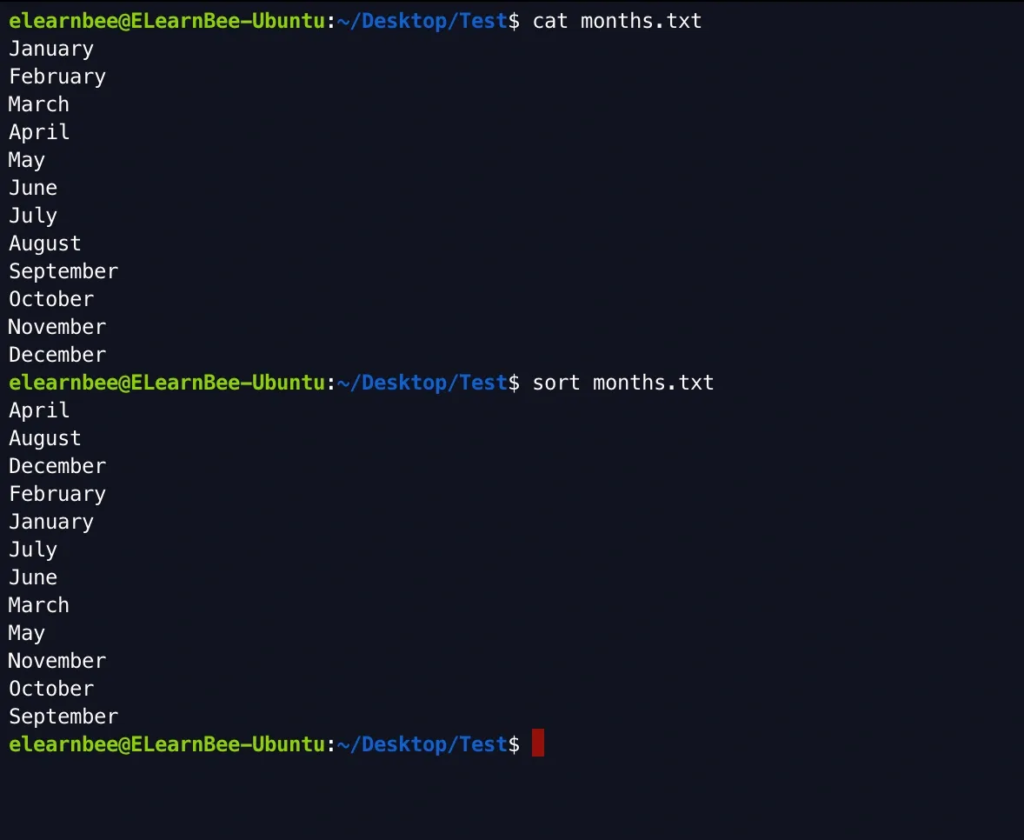
uniq
- The “uniq” command is used to report or exclude duplicate lines.
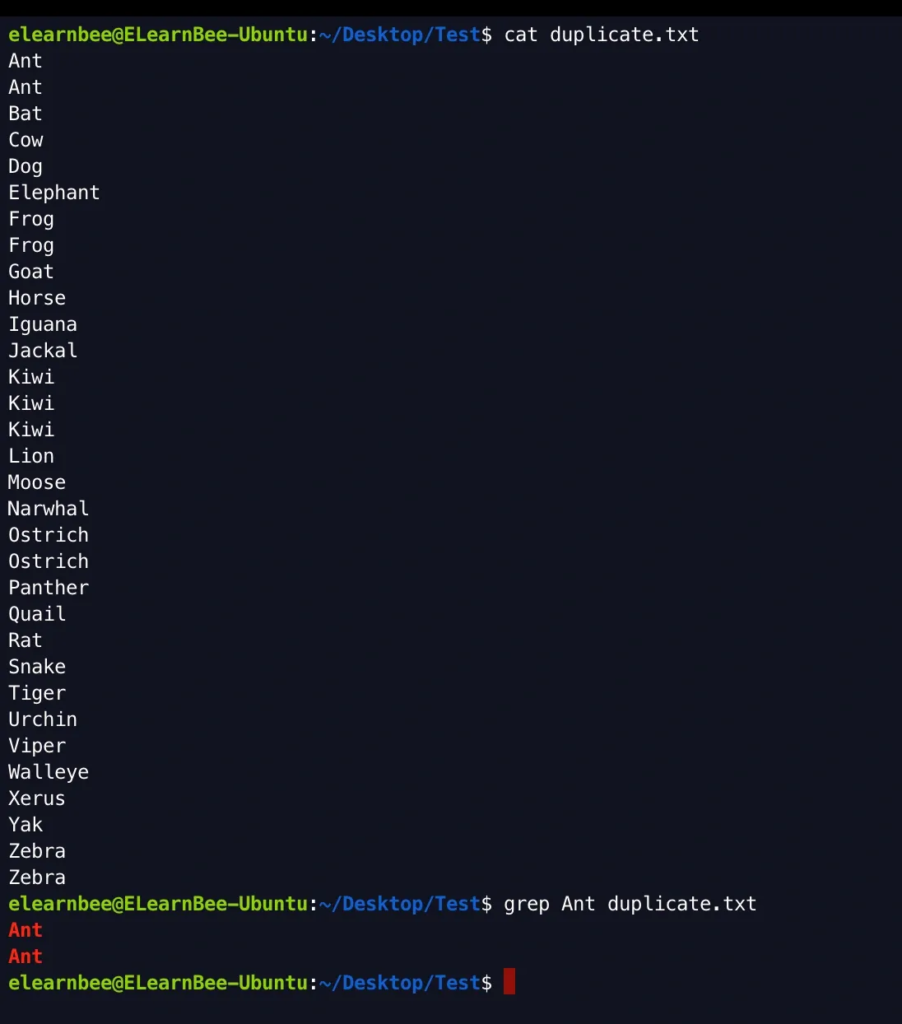
uniq duplicate.txt wc
- “wc” command assists in counting the lines, words, and characters in a file. It shows the number of lines, characters, and words included in a file.
wc elb.txt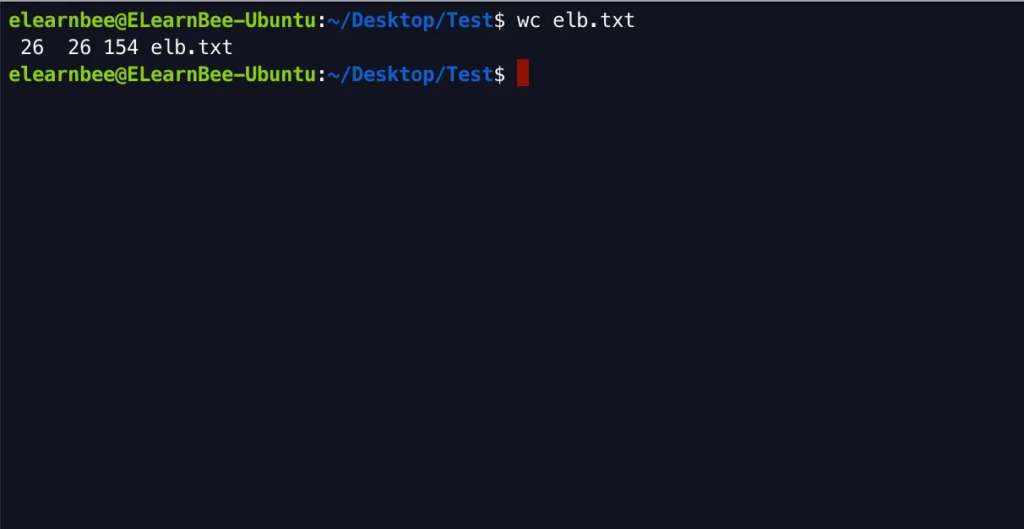
Here, “wc” gives 4 outputs as follows:
- number of lines
- number of words
- number of characters
- path
grep
- The “grep, egrep, fgrep”, and “rgrep” commands all do the same thing. It will be useful to filter or pull out the pattern string that matches from the data or file that was given as input.
grep Ant duplicate.txt